AI News
Meet FineWeb: A Promising 15T Token Open-Source Dataset for Advancing Language Models
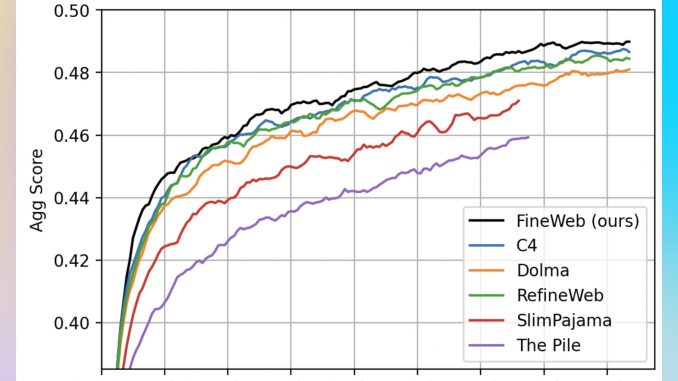
FineWeb, a newly released open-source dataset, promises to propel language model research forward with its extensive collection of English web data. Developed by a consortium led by huggingface, FineWeb offers over 15 trillion tokens sourced […]