


The robotics research field has significantly transformed by integrating large language models (LLMs). These advancements have presented an opportunity to guide robotic systems in solving complex tasks that involve intricate planning and long-horizon manipulation. While robots have traditionally relied on predefined skills and specialized engineering, recent developments show potential in using LLMs to help guide reinforcement learning (RL) policies, bridging the gap between abstract high-level planning and detailed robotic control. The challenge remains in translating these models’ sophisticated language processing capabilities into actionable control strategies, especially in dynamic environments involving complex interactions.
Robotic manipulation tasks often require executing a series of finely tuned behaviors, and current robotic systems struggle with the long-horizon planning needed for these tasks due to limitations in low-level control and interaction, particularly in dynamic or contact-rich environments. Existing tools, such as end-to-end RL or hierarchical methods, attempt to address the gap between LLMs and robotic control but often suffer from limited adaptability or significant challenges in handling contact-rich tasks. The primary problem revolves around efficiently translating abstract language models into practical robotic control, traditionally limited by LLMs’ inability to generate low-level control.
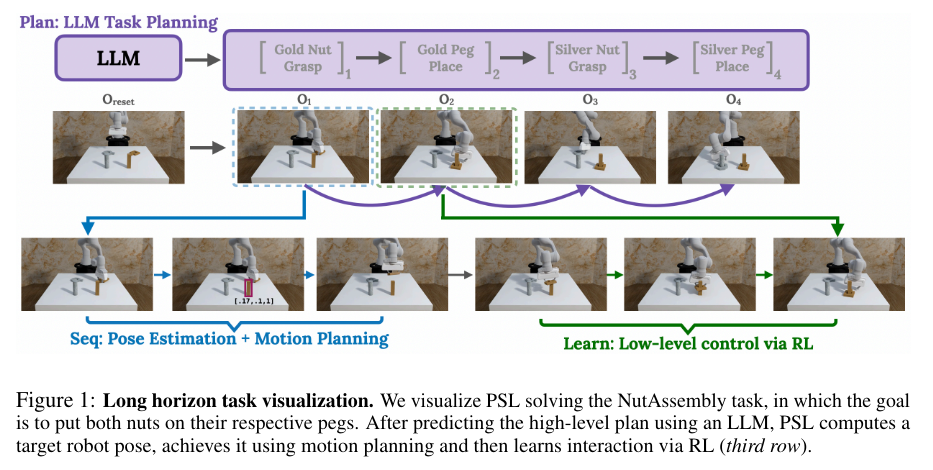
The Plan-Seq-Learn (PSL) framework by researchers from Carnegie Mellon University and Mistral AI is introduced as a modular solution to address this gap, integrating LLM-based planning for guiding RL policies in solving long-horizon robotic tasks. PSL decomposes tasks into three stages: high-level language planning (Plan), motion planning (Seq), and RL-based learning (Learn). This allows PSL to handle both contact-free motion and complex interaction strategies. The PSL system leverages off-the-shelf vision models to identify the target regions of interest based on high-level language input, providing a structured plan for sequencing the robot’s actions through motion planning.
PSL uses an LLM to generate a high-level plan that sequences robot actions through motion planning. Vision models help predict regions of interest, allowing the sequencing module to identify target states for the robot to achieve. The motion planning component drives the robot to these states, and the RL policy takes over to perform the required interactions. This modular approach allows RL policies to refine and adapt control strategies based on real-time feedback, enabling a robotic system to navigate complex tasks. The research team demonstrated PSL across 25 complex robotics tasks, including contact-rich manipulation tasks and long-horizon control tasks involving up to 10 stages. This involved tasks with up to 10 sequential stages requiring up to 10 separate robotic sub-tasks.

PSL achieved a success rate above 85%, significantly outperforming existing methods like SayCan and MoPA-RL. This was particularly evident in contact-rich tasks, where PSL’s modular approach enabled robots to adapt to unexpected conditions in real-time, efficiently solving the complex interactions required. The flexibility of the PSL framework allows for a modular combination of planning, motion, and learning, enabling it to handle different types of tasks from a wide range of robotics benchmarks. By sharing RL policies across all stages of a task, PSL achieved remarkable efficiency in training speed and task performance, outstripping methods like E2E and RAPS.

In conclusion, the research team demonstrated the effectiveness of PSL in leveraging LLMs for high-level planning, sequencing motions using vision models, and refining control strategies through RL. PSL achieves a delicate balance of efficiency and precision in translating abstract language goals into practical robotic control. Modular planning and real-time learning make PSL a promising framework for future robotics applications, enabling robots to navigate complex tasks involving multi-step plans.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

Be the first to comment