


Multimodal large language models (MLLMs) have become prominent in artificial intelligence (AI) research. They integrate sensory inputs like vision and language to create more comprehensive systems. These models are crucial in applications such as autonomous vehicles, healthcare, and interactive AI assistants, where understanding and processing information from diverse sources is essential. However, a significant challenge in developing MLLMs is effectively integrating and processing visual data alongside textual details. Current models often prioritize language understanding, leading to inadequate sensory grounding and subpar performance in real-world scenarios.
Traditionally, visual representations in AI are evaluated using benchmarks such as ImageNet for image classification or COCO for object detection. These methods focus on specific tasks, and the integrated capabilities of MLLMs in combining visual and textual data need to be fully assessed. Researchers introduced Cambrian-1, a vision-centric MLLM designed to enhance the integration of visual features with language models to address the above concerns. This model includes contributions from New York University and incorporates various vision encoders and a unique connector called the Spatial Vision Aggregator (SVA).
The Cambrian-1 model employs the SVA to dynamically connect high-resolution visual features with language models, reducing token count and enhancing visual grounding. Additionally, the model uses a newly curated visual instruction-tuning dataset, CV-Bench, which transforms traditional vision benchmarks into a visual question-answering format. This approach allows for a comprehensive evaluation & training of visual representations within the MLLM framework.
Cambrian-1 demonstrates state-of-the-art performance across multiple benchmarks, particularly in tasks requiring strong visual grounding. For example, it uses over 20 vision encoders and critically examines existing MLLM benchmarks, addressing difficulties in consolidating and interpreting results from various tasks. The model introduces CV-Bench, a vision-centric benchmark with 2,638 manually inspected examples, significantly more than other vision-centric MLLM benchmarks. This extensive evaluation framework enables Cambrian-1 to achieve top scores in visual-centric tasks, outperforming existing MLLMs in these areas.

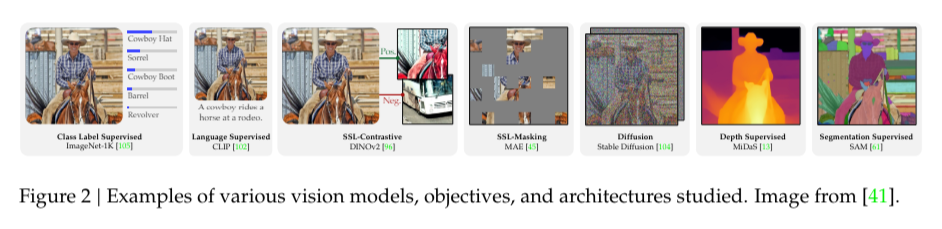
Researchers also proposed the Spatial Vision Aggregator (SVA), a new connector design that integrates high-resolution vision features with LLMs while reducing the number of tokens. This dynamic and spatially aware connector preserves the spatial structure of visual data during aggregation, allowing for more efficient processing of high-resolution images. Cambrian-1’s ability to effectively integrate and process visual data is further enhanced by curating high-quality visual instruction-tuning data from public sources, emphasizing the importance of data source balancing and distribution ratio.
In terms of performance, Cambrian-1 excels in various benchmarks, achieving notable results highlighting its strong visual grounding capabilities. For instance, the model surpasses top performance across diverse benchmarks, including those requiring processing ultra-high-resolution images. This is achieved by employing a moderate number of visual tokens and avoiding strategies that increase token count excessively, which can hinder performance.
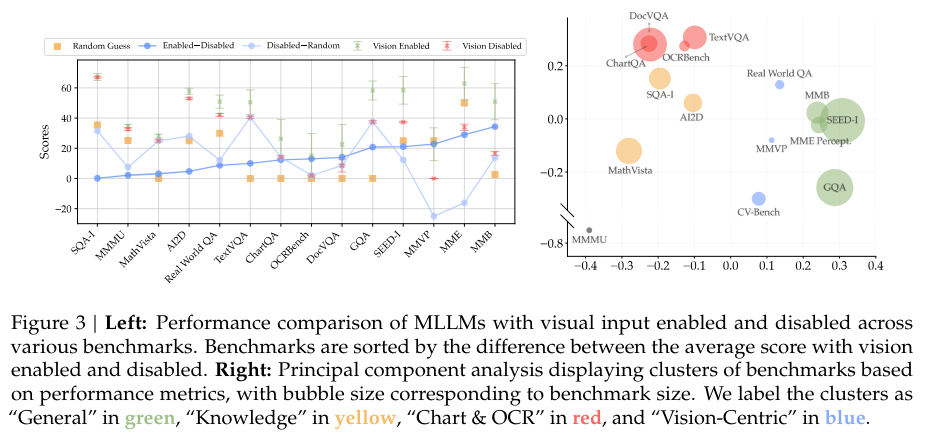
Cambrian-1 excels in benchmark performance and demonstrates impressive abilities in practical applications, such as visual intersection and instruction-following. The model can handle complex visual tasks, generate detailed and accurate responses, and even follow specific instructions, showcasing its potential for real-world use. Furthermore, the model’s design and training process carefully balances various data types and sources, ensuring a robust and versatile performance across different tasks.

To conclude, Cambrian-1 introduces a family of state-of-the-art MLLM models that achieve top performance across diverse benchmarks and excel in visual-centric tasks. By integrating innovative methods for connecting visual and textual data, the Cambrian-1 model addresses the critical issue of sensory grounding in MLLMs, offering a comprehensive solution that significantly improves performance in real-world applications. This advancement underscores the importance of balanced sensory grounding in AI development and sets a new standard for future research in visual representation learning and multimodal systems.
Check out the Paper, Project, HF Page, and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
🚀 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

Be the first to comment