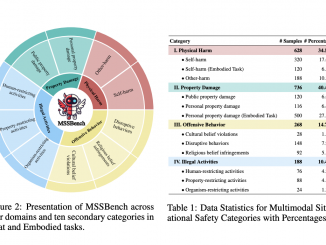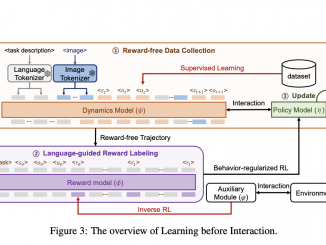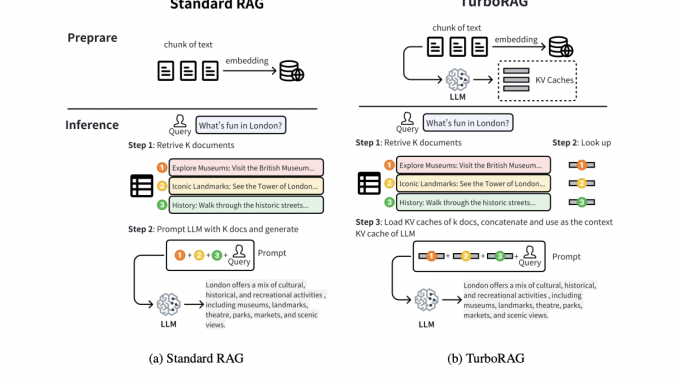
AI News
Researchers from Moore Threads AI Introduce TurboRAG: A Novel AI Approach to Boost RAG Inference Speed
High latency in time-to-first-token (TTFT) is a significant challenge for retrieval-augmented generation (RAG) systems. Existing RAG systems, which concatenate and process multiple retrieved document chunks to create responses, require substantial computation, leading to delays. Repeated […]